Anti-Trust Rank算法详解
一、简介
Anti-Trust Rank算法经过Trust Rank算法思想而设计出,由作弊的页面开始,向相反的方向传播反信任值(也就是作弊值),目的是检测垃圾页面,然后由搜索引擎过滤。Anti-Trust Rank算法准则大致等同于Trust Rank算法即好的页面很少指向垃圾页面。这个原则其实也暗示了一点,那就是指向垃圾页面的有很大的可能也是垃圾页面。Trust Rank算法从一组可信赖的页面开始,经过外链接将信任值进行传播。同样的,在Anti-Trust Rank算法中,从一组垃圾种子页面开始,通过内链接(即外链接指向这些垃圾页面的网页)反向传播传播反信任值。我们可以设置一个阀值如果页面的反信任值高于这个阀值,就可归类为作弊网页。
二、公式使用
对于Anti-Trust Rank算法来说,我们首先要做的是选取种子页面,注意与Trust Rank算法不同的是,Anti-Trust Rank算法选取的是作弊网页作为种子页面。
Anti-Trust Rank算法的计算公式为:
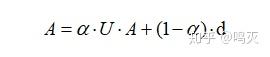
其中α为衰减因子取值一般为0.80或0.85,关系矩阵U的计算公式如下: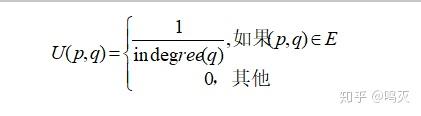
初始值A的公式为: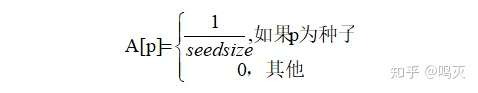
初始值d的公式为: 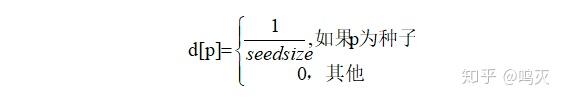
三、算法示例
我们首先设计一个网站链接关系图,圆代表不同的网站或网页,圆之间的箭头代表网站之间的链接关系: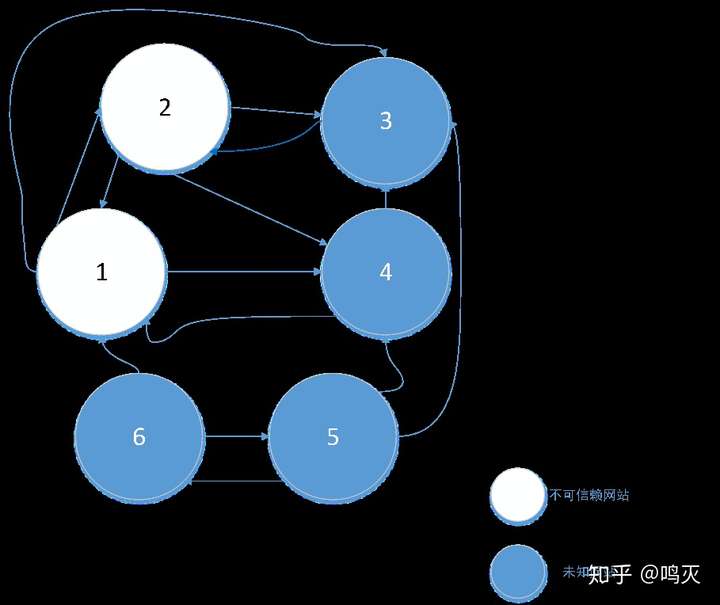

注意,此时的U与Trust Rank算法中的T是不同的,然后按照公式迭代,不断更新A的值。





