机器学习系列四—逻辑回归
我们在前面讲了线性回归模型,它可以对数据进行预测、拟合。假设有一个二元分类的问题,最终的结果有两类(0,1),此时我们如果使用线性回归模型,那么他的输出结果可能远大于1,或者小于0。这时候我们就需要一个算法使结果的输出一直处于(0,1)之间,这就是我们接下来要讲的逻辑回归算法。它在原有的线性回归算法外面,加上了一个sigmoid函数,使之输出一直处于0,1之间。
Sigmoid函数的公式为:
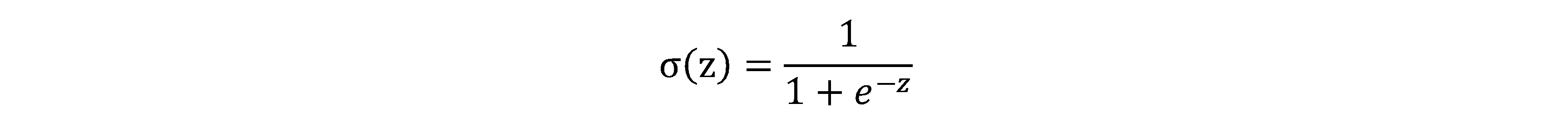
其中z为我们前面所说的线性函数:
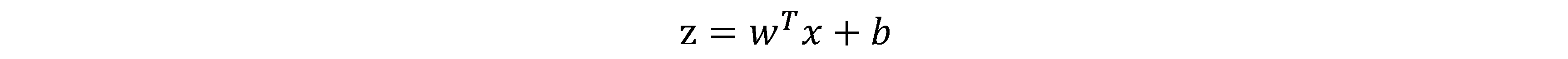
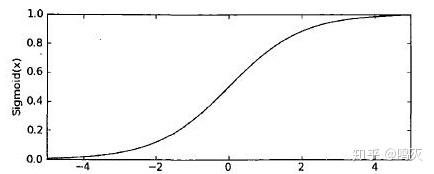
这样最终的预测值就会处于0,1之间,我们将大于0.5的分类为1,小于0.5的分类为0。至于说为什么外面加上sigmiod函数预测值就处于0,1之间,大家可以考虑z,当z特别大时sigmiod函数就会接近1,z非常小时,sigmiod就会非常接近0。下面是sigmiod函数的图像,大家可以自己感受下
损失函数
我们在之前将线性回归的时候讲解了损失函数,但现在我们逻辑回归函数的损失函数与线性回归的损失函数是不同的,线性回归之中用到的损失函数为:
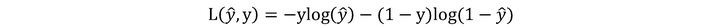
至于说为什么使用这个函数作为逻辑损失函数?大家可以考虑下:
当y=1时,损失函数
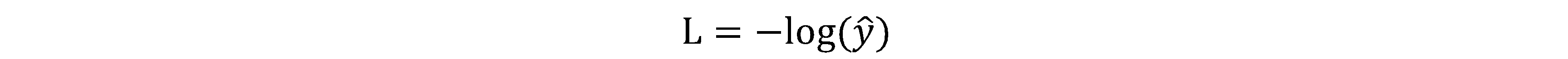
如果想损失函数L尽可能小,那么预测值就要尽可能大,因为sigmiod函数取值[0,1],因此预测值会无限接近1。
当y=0时,损失函数
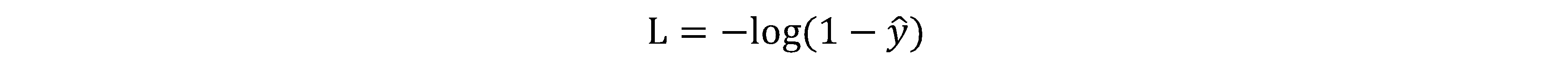
如果想损失函数L尽可能小,那么预测值就要尽可能小,因为sigmiod函数取值[0,1],因此预测值会无限接近0。
参考:吴恩达深度学习视频



















