一种通用论坛内容提取方法
很久之前参加了个比赛,实现了一个提取论坛内容的算法。
一、挖掘目标
将论坛之中的内容按以下方式存储:

二、总体流程
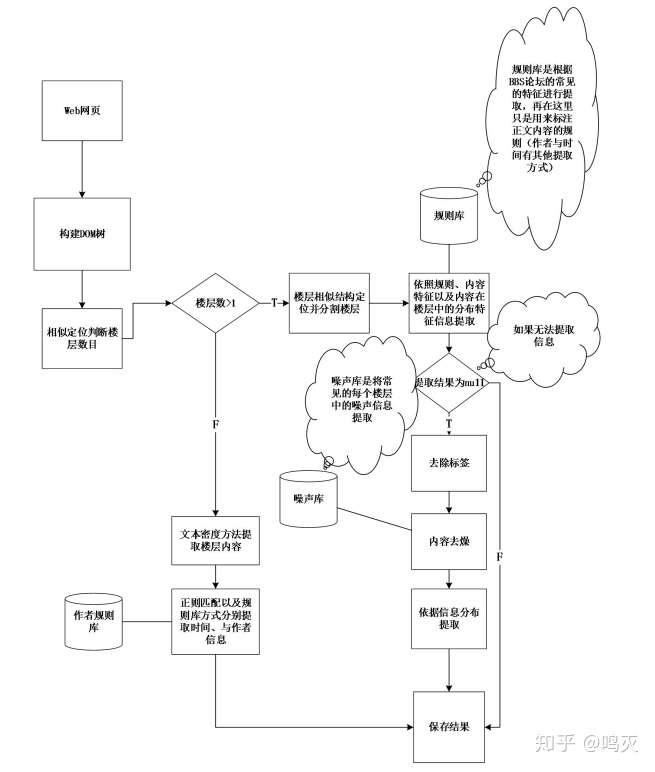
三、主要贡献
本文做的主要贡献是实现了根据楼层相似结构地位并分割楼层。
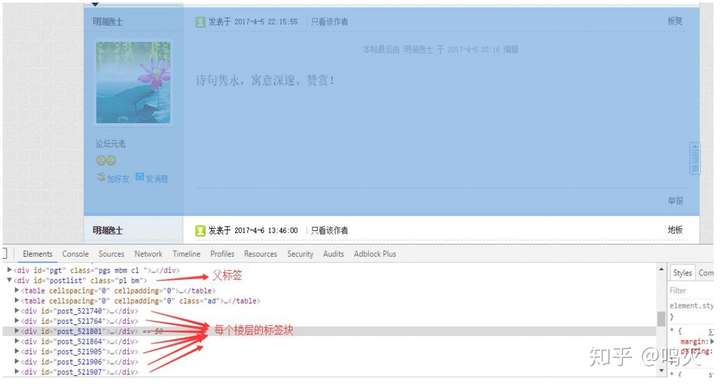
我们查看BBS论坛页面的网页结构发现以下特征:
1.在同一个web页面中,每个楼层所在的DOM结构的节点的子树都很相似。
2.不同楼层都位于同一个父节点下面。
3.不同楼层之间为兄弟节点。
如下图所示:
楼层分割算法具体步骤:
1.筛选标签
首先将web页面转化为DOM结构,找出不可能成为节点的标签并剔除例如:
<link><head><p>......
对于一个帖子而言,有这么几方面重要的内容:作者、时间、正文内容,这三个方面之中,作者、正文内容结构是难以预测的,但是时间我们可以通过使用正则表达式进行匹配。因此,我们遍历出所有节点,将节点中不含有时间的节点剔除。
另外我们发现,一个楼层块中必定有很多的标签块,如作者、时间、内容等等,我们对每个楼层下的节点进行递归循环,发现楼层下的标签数量比较多,因此我们设置一个阈值进行过滤。将的标签数目少的节点过滤。
2.定位楼层
经过以上几个步骤之后,我们将每一块与他的所有兄弟节点进行比较,找到相同的块,并作为一个列表存储。如下图:
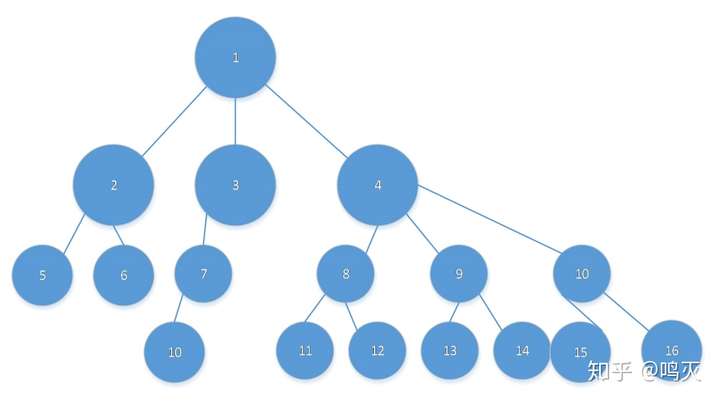
将2、3与4进行比较,8、9、10进行比较,最终我们会得到几个列表:
[2] [3] [4] [5,6] ...[8,9,10]...
列表内节点个数最多的为楼层序列。
评论已关闭